









Forcepoint Data Classification

Software Data Classification
Classificazione e report con sicurezza
Classifica in modo preciso ed efficiente la più ampia gamma di tipi di dati con una maggiore accuratezza grazie alla tecnologia AI Mesh.
Trova e cataloga i dati in tutta l'azienda alla velocità della luce.

Perché scegliere Forcepoint Data Classification?


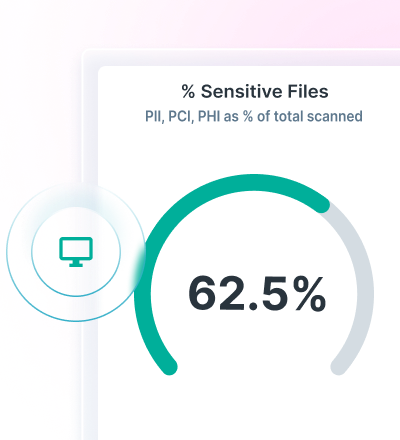
La copertura della più ampia gamma di tipi di dati del settore aiuta a semplificare la conformità, il tutto fornendo una protezione migliore per i dati delle organizzazioni.


AI Mesh classifica i dati in modo rapido e preciso in pochi millisecondi, semplificando i processi e riducendo gli sforzi manuali per consentire ai team di concentrarsi su attività di valore più elevato o incidenti più significativi.


Protezione dei dati ovunque sia necessario.
Proteggi i dati ovunque con Forcepoint. Previeni le violazioni, semplifica la conformità, unifica la gestione delle politiche e adattati al rischio in tempo reale con le nostre soluzioni di protezione dei dati.

Forcepoint DLP: Proteggi le informazioni sensibili e applica la conformità con il DLP Software-as-a-Service (SaaS).
DSPM (Data Security Posture Management): automatizza la scoperta dei dati, la classificazione e l'orchestrazione per ottenere il controllo e la visibilità totali dei tuoi dati in tutta l'azienda.
Risk-Adaptive Protection: regola automaticamente le politiche in base al comportamento degli utenti per adattarsi in tempo reale ai rischi emergenti.
Domande frequenti
Cos'è Data Classification?
Data Classification è la pratica di etichettare e organizzare i dati in categorie predefinite, che semplifica la localizzazione e il recupero e garantisce l'accesso sicuro per gli utenti autorizzati.
Perché Data Classification è importante per le organizzazioni?
Le pratiche di Data Classification sono necessarie per mantenere una solida postura di sicurezza. Garantendo che i team di sicurezza sappiano dove trovare le informazioni sensibili e impostando regole su chi è autorizzato ad avere accesso, è possibile prevenire o contenere le violazioni dei dati e tenere gli utenti non autorizzati lontani dalle risorse che non dovrebbero avere.
Quali sono i tipi di Data Classification?
Classificazione basata sui contenuti: questa è la pratica di esaminare i file e cercare le informazioni sensibili al loro interno. Ciò può essere utile se si ha un problema di informazioni riservate che si nascondono in tipi di file apparentemente innocui.
Classificazione basata sul contesto: invece di esaminare direttamente i contenuti dei file, questo approccio esamina principalmente i metadati associati ai file per trovare indizi che indicano che i dati all'interno sono sensibili. Ciò può includere l'identificazione della posizione in cui viene salvato un file, dell'utente che lo ha creato o per quale applicazione è stato creato il file. Questo approccio funziona bene quando la tua base di utenti è ben formata e quando hai già un grado di controllo sui tuoi dati sensibili.
Classificazione basata sugli utenti: questo approccio richiede agli utenti di esaminare i file e classificarli. Sebbene nel migliore dei casi questo approccio possa ridurre significativamente i falsi positivi, si basa non solo sulla disponibilità di una base di utenti altamente qualificata ma anche sul tempo necessario per classificare manualmente i dati. Ciò significa che in genere è adatto solo per un'organizzazione più snella o un set di dati più piccolo.
Quali sono le migliori pratiche per implementare la Data Classification?
Identificazione: trova la posizione dei tuoi dati sensibili, inclusi i repository cloud e i dischi rigidi fisici, e adotta i passaggi immediati necessari per proteggerli con la Crittografia, i controlli dell'accesso fisico, ecc. Organizzazione: crea il processo che utilizzerai per organizzare i dati in categorie. Formazione: autorizza i dipendenti ad assumere un ruolo nell'etichettare i dati e collocarli nella posizione corretta in base alla loro categoria. Più persone hanno un ruolo nel processo, più rigorosa deve essere la formazione per garantire che l'errore umano non comprometta i tuoi sforzi.
Conformità: comprendi la protezione dei dati e la Riservatezza dei dati applicabili per le tue operazioni, insieme alle sanzioni per la mancata conformità.
Soluzioni: individua la soluzione di Data Classification che si adatta meglio alla tua organizzazione. In molti casi può essere meglio utilizzare una piattaforma di sicurezza dei dati completa che può assistere con il rilevamento, la classificazione e la priorità dei dati anziché raggruppare soluzioni diverse di vari fornitori.
La Data Classification può aiutare con la Conformità alle normative?
Sì, Forcepoint Data Classification può aiutare a semplificare la conformità in oltre 80 regioni. Ti aiuta a evitare le multe costose per mancata conformità con le normative chiave pronte all'uso e la più ampia copertura di tipi di dati del settore.
Quanto è accurata Forcepoint Data Classification?
Forcepoint Data Classification utilizza la precisione e l'efficienza basate sull'IA. Aiuta a classificare i dati su più fonti, utilizzando la tecnologia AI Mesh, per migliorare continuamente la loro precisione ed efficienza, risparmiando alle organizzazioni tempo e risorse preziose.
Cos'è AI Mesh e come viene utilizzato?
Forcepoint Data Classification utilizza AI Mesh per fornire una classificazione dei dati altamente accurata. La sua architettura IA in rete si basa su un modello linguistico di piccole dimensioni e su componenti IA avanzati per migliorare l'efficienza e ridurre i falsi positivi.
