
DSPM (Data Security Posture Management)
12,000명 이상의 고객이 잘못할 수 없습니다














민감한 데이터에 대한 가시성 및 제어 확보
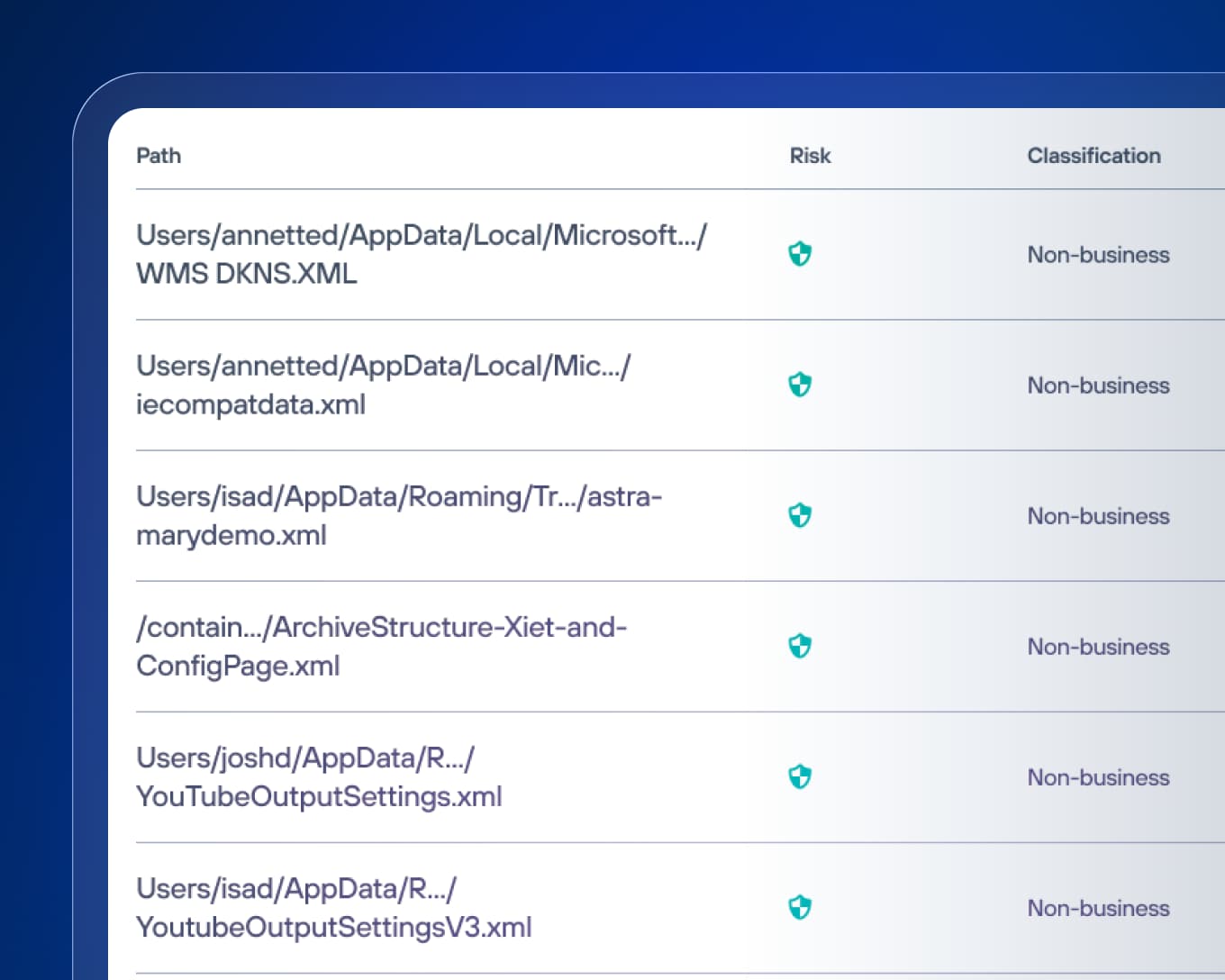
광범위한 데이터 검색과 매우 정확한 분류를 통해 다크 데이터에 빛을 비춥니다.
Forcepoint DSPM 소프트웨어는 모든 데이터 소스를 스캔하고 독점적인 AI Mesh 기술을 사용하여 고위험 데이터를 식별, 분류 및 수정합니다.
보안 팀이 다음과 같은 문제로 어려움을 겪고 있다면, 이것은 완벽한 솔루션입니다:

대량의 섀도우 데이터
과도한 권한을 가진 데이터
GenAI 데이터 유출 위험
미확인 데이터 위치
Forcepoint DSPM Software Leads the Pack
Forcepoint is the only Data Security Posture Management vendor that uses AI Mesh technology to deliver highly accurate data classification. Read the full comparison chart to learn why organizations trust the leading data security provider to discover and catalogue data and remediate risk at scale.
Forcepoint
100%
Traditional Vendor
57%
Data Governance Vendor
36%
Forcepoint DSPM이 최고 평가를 받은 보안 도구인 이유
데이터 가시성 향상
클라우드와 온프레미스 환경 전반의 정형화와 비정형화된 데이터에 대한 완전한 가시성을 확보하여 어디에 있든 민감한 데이터를 추적하고 관리합니다.
AI를 통한 검색 및 분류
매우 정확한 AI Mesh 기술을 활용하여 효율적이고 안정적인 데이터 검색 및 분류를 수행하여 오탐을 줄이고 사고 경보의 정확성을 향상시킵니다.
사전 예방적인 위험 개선
실행 가능한 인사이트를 통해 권한을 관리하고, 잘못된 위치된 데이터를 이동하며, 데이터 주권성, 데이터 액세스 및 중복 또는 ROT 문제를 해결할 수 있습니다.
규정 준수 관리 자동화
자동화를 통해 규정 준수 프로세스를 간소화하여 진화하는 규정에 대해 일관되고 지속적인 조정을 보장하여 수동적인 노력을 줄입니다.

정확성과 투명한 보고 정확성 및
FBD Insurance의 CTOO인 Enda Kyne는 DSPM 및 DDR이 중요한 데이터를 제어하고 규제 기관에 활동을 보고하기 위해 그의 IT 보안 및 데이터 보호 팀에서 도입되어 왔다고 말합니다.
Strengthen Your Data Security Posture


Rapidly and precisely identify sensitive data-at-rest with AI Mesh technology that fine-tunes its classification accuracy relative to your unique organizational needs.
Extend visibility and control over all your regulated data, eliminate gaps and generate automated reports to demonstrate compliance.
Gain a centralized view of your data and enforce the Principle of Least Privilege across cloud, SaaS and on-prem systems for effective governance.


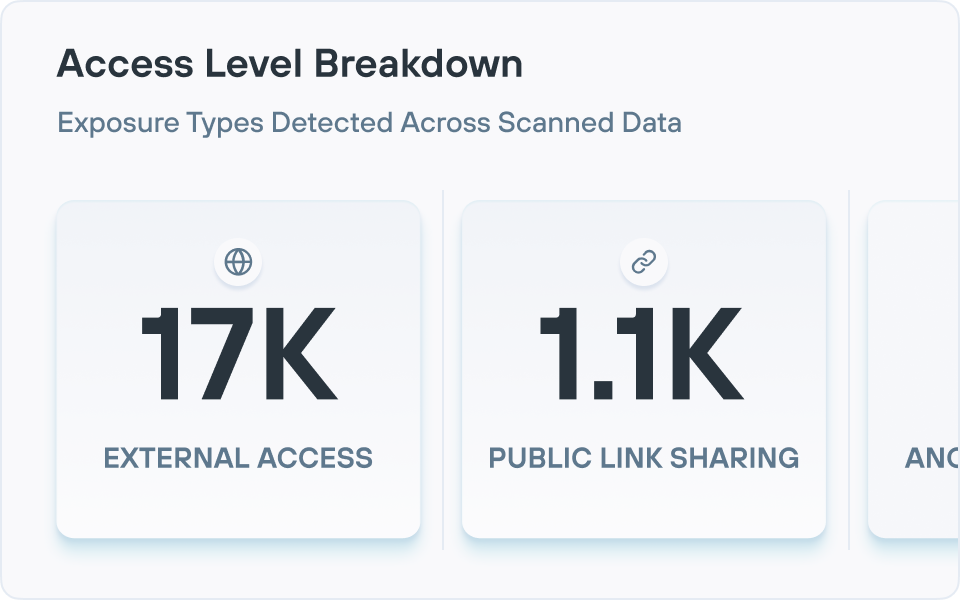
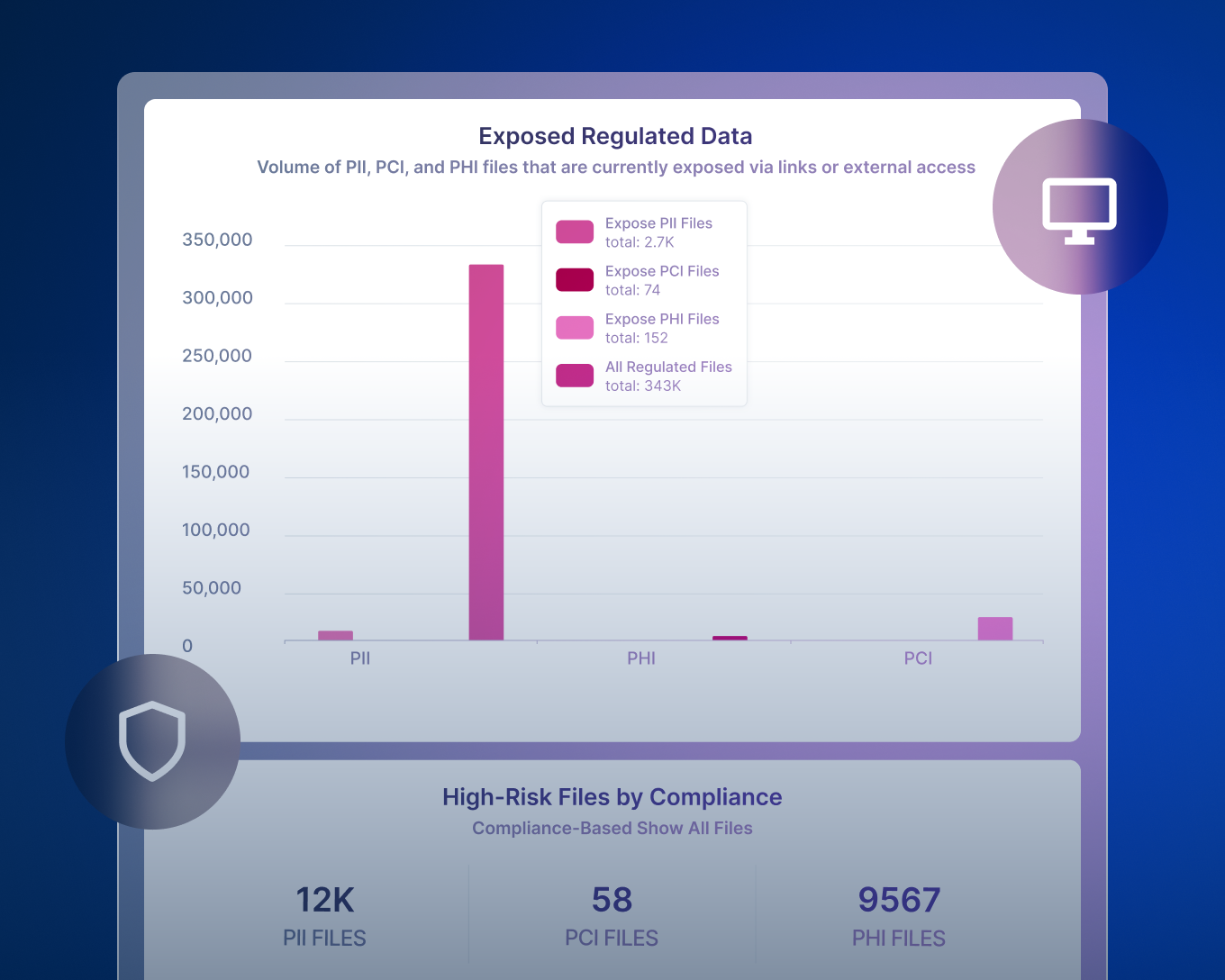
데이터가 위험에 노출되어 있나요?
데이터 위험 평가는 미분류 민감 파일, 과도한 권한을 가진 사용자와 같은 데이터 위협 요소를 선제적으로 발견합니다. Forcepoint의 무료 데이터 위험 평가를 통해 DSPM의 기능을 직접 체험해 보고 내 데이터가 얼마나 안전한지 확인해 보세요.


데이터 검색, 분류, 보호 및 수정을 위해 DLP, DSPM 및 DDR을 통합하는 기능.
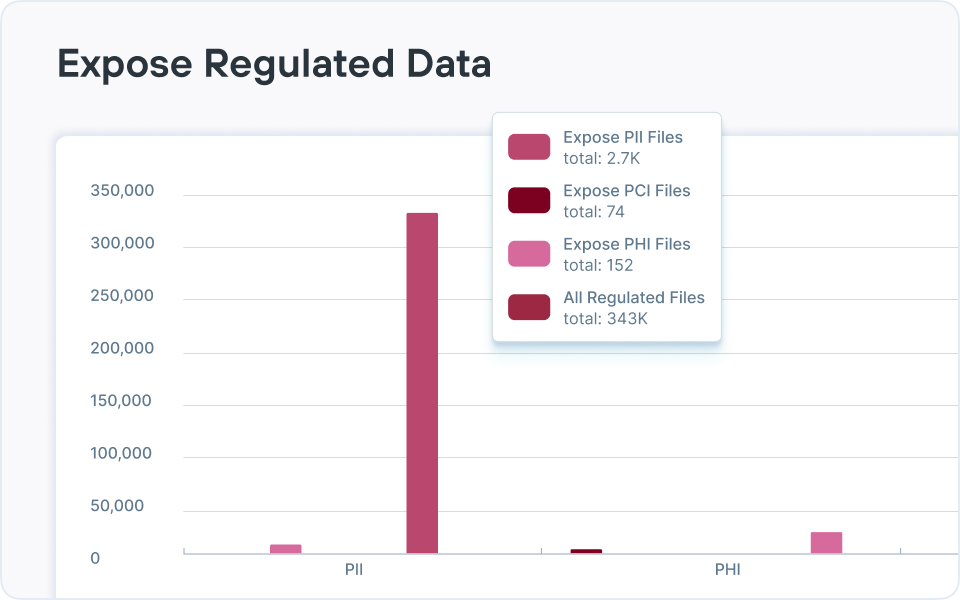
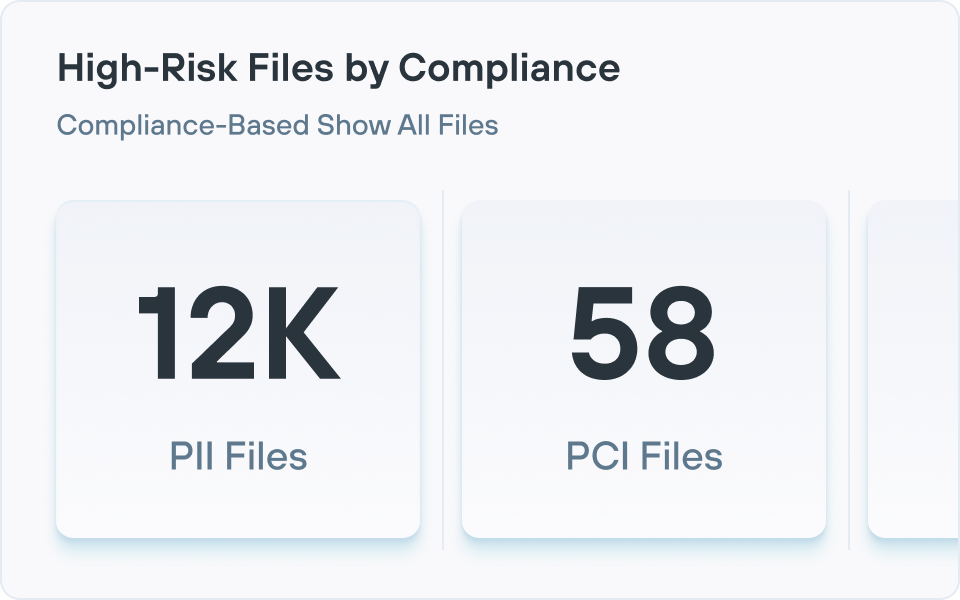
ROT(중복되고, 오래되고, 중요하지 않은) 데이터, 과도한 권한을 가진 데이터, 데이터 주권 문제 및 전체 데이터 상태를 위험하게 만드는 기타 많은 문제들을 볼 수 있는 효과적인 위험 보고를 제공합니다.
모든 GenAI 애플리케이션에 대한 데이터 준비에 대한 가시성과 제어권을 제공합니다. 또한 Copilot 및 ChatGPT Enterprise 사용을 보호할 수 있습니다.
고객 사례
As part of Forcepoint’s broader data security ecosystem, DSPM has integrated seamlessly with our existing solutions. It’s an essential component of our overall data security strategy.
Indonesia Financial Group (IFG)

...A robust, AI-driven approach to Data Security Posture Management... truly a must have tool for any organization who want(s) their company to be secured.
Forcepoint DSPM gave us a clearer understanding of data exposure and made it easier to prove the compliance to the auditors.
Forcepoint DSPM gives a clear overview and data visibility across all cloud environments... Helpful tool for keeping an eye on sensitive data, especially in the cloud.
고객 사례
"As part of Forcepoint’s broader data security ecosystem, DSPM has integrated seamlessly with our existing solutions. It’s an essential component of our overall data security strategy."
Indonesia Financial Group (IFG)
분석가가 추천합니다.
사용자가 인정합니다.
Forcepoint는 사용자와 업계 분석가들이 선정한 최고의 Data Loss Prevention 소프트웨어 및 데이터 보안 소프트웨어 공급업체 중 하나로 꾸준히 선정되었습니다.
Forcepoint가 IDC MarketScape: Worldwide DLP 2025 Vendor Assessment에서 리더로 선정되었습니다.
Forcepoint가 Frost & Sullivan에서 선정한 2024년 글로벌 DLP 올해의 기업 으로 2년 연속 선정되었습니다.
Forcepoint가 2025년 1분기 The Forrester Wave™: Data Security Platforms에서 우수 성과 를 거두는 기업으로 선정되었습니다.
Data Security Posture Management 모범 사례 구현



자주 묻는 질문
데이터 보안 상태 관리(DSPM)란 무엇인가요?
데이터 보안 상태 관리는 민감한 데이터가 어디에 있고, 어떻게 기밀되고, 클라우드, SaaS 및 온프레미스 환경 전체에서 누가 액세스할 수 있는지 지속적으로 발견해 주는 보안 솔루션입니다.
Forcepoint의 AI 네이티브 DSPM은 이와 동일한 모델을 따릅니다. 정형 및 비정형 데이터를 지속적으로 인벤토리로 작성하고, AI 메시 기술을 사용하여 파일 스토리지, 클라우드 앱, 온프레미스 위치 전반에서 해당 데이터를 정확하게 분류하고, 다양한 렌즈를 통해 해당 데이터가 위험에 노출되어 있는지 여부를 평가합니다.
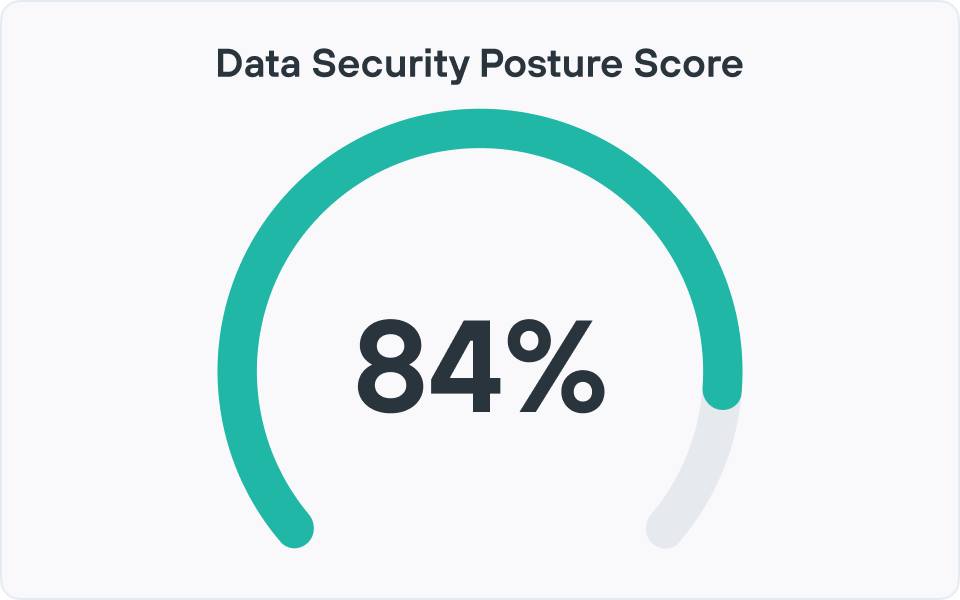
Forcepoint DSPM은 정기적인 감사에서 데이터 위험에 대한 실시간 뷰로 전환하여 생산성을 높이고, 비용을 절감하며, 위험을 줄이고, 규정 준수를 간소화하는 데 도움이 됩니다.
DSPM 솔루션은 어떤 방식으로 작동하나요?
대부분의 DSPM 플랫폼은 반복적인 수명 주기를 따릅니다. 데이터(여러 클라우드와 온프레미스에서 정형 및 비정형)를 발견하고, 민감도와 비즈니스 컨텍스트에 따라 분류하고, 위험(예: 과도한 권한이 있는 액세스나 잘못된 위치에 있는 데이터)을 평가하고 우선순위를 정하고, 잘못된 구성이나 안전하지 않은 액세스를 수정하고, 최신 상태를 유지하기 위해 지속적으로 모니터링합니다.
Forcepoint DSPM은 소규모 언어 모델과 딥 뉴럴 네트워크를 사용하는 AI 분류 아키텍처인 AI 메쉬를 통해 이를 구현합니다. Forcepoint DSPM은 통합된 데이터 소스를 스캔하고, 고위험 데이터를 식별 및 분류하며, 팀이 권한을 조정하고, 잘못된 위치를 옮기고, 중복되거나, 오래되거나, 중요하지 않은(ROT) 데이터를 정리하고, 보고서에서 멈추는 대신에 주권(sovereignty) 문제를 해결할 수 있도록 다음 수정단계를 권장합니다.
최근 업데이트는 Forcepoint DSPM을 파일뿐만 아니라 엔터프라이즈 데이터베이스와 데이터 레이크로 확장하였기 때문에, 동일한 발견, 분류, 적응형 적용 모델이 이제 Forcepoint DDR 및 DLP와 함께 단일 통합 플랫폼에서 정형과 비정형의 데이터를 모두 포함하고 있습니다.
DSPM 소프트웨어의 데이터 검색 기능은 어떤 식으로 작동하나요?
DSPM은 클라우드, 네트워크, 온프레미스 스토리지 전반에서 데이터를 지속적으로 발견하여 조직이 보유한 모든 데이터를 찾아내고 목록화합니다. 민감한 데이터를 찾아내는 것은 데이터를 보호하기 위한 중요한 첫 단계입니다. DSPM 솔루션은 다음과 같은 전체 데이터 에코시스템을 스캔합니다.
- 클라우드 플랫폼(AWS, Azure, GCP)
- SaaS 애플리케이션(Microsoft 365, Salesforce)
- 온프레미스 스토리지 및 데이터베이스
최신 DSPM 소프트웨어는 내장 기능 또는 솔루션 통합을 통해 데이터가 이동하고 변경될 때 지속적인 가시성을 유지합니다.
DSPM 솔루션은 어떤 데이터 분류 및 위험 평가 기능을 제공하나요?
완성된 DSPM 솔루션은 다음과 같은 기능 체인을 제공합니다.
- 데이터 발견 및 AI 기반 분류: 클라우드, SaaS, 엔드포인트 및 온프레미스 저장소를 자동으로 스캔하고, 미세하게 조정된 AI를 사용하여 민감도와 비즈니스 목적에 따라 정형화된 데이터와 비정형화를 정확하게 분류하며, 오탐을 줄이기 위해 조정 가능한 모델을 사용합니다.
- 데이터 위험 평가와 위험 분석 및 우선순위 지정: 민감한 데이터의 인벤토리를 구축한 다음 노출, 과도한 액세스, 비즈니스 영향 등을 기반으로 위험 점수를 매기므로 팀은 가장 중요한 데이터 세트에 먼저 집중합니다. Forcepoint는 위험 점수와 재정적 영향 추정치를 사용하여 완화의 우선순위를 매기고 있습니다.
- 액세스 거버넌스: 디렉터리 통합을 통해 권한에 대한 심층적인 가시성으로 누가 어떤 데이터에 액세스하는지 보여주고, 공개 또는 외부 공유, 비활성 계정, 과도한 공유 폴더를 강조합니다.
- 규제 및 보고: 규제 데이터를 매핑하고, 통제를 문서화하고, 감사를 간소화하는 대시보드, 감사 추적 및 프레임워크 조정 보고서(GDPR 또는 HIPAA 같은 규정용)를 생성합니다. Forcepoint는 정책 템플릿, 자동 보고, 설명 가능한 AI 분류를 추가하여 하이브리드 환경 전체에서 규정 준수 입증을 간소화합니다.
DSPM 플랫폼은 조직이 위험을 관리하고 해결하는 데 어떤 도움을 주나요?
해결책 없이 문제를 식별하면 가치가 거의 없습니다. 최신 DSPM 플랫폼은 조직의 고유한 필요와 과제에 적응하는 사용자 지정 가능한 제어로 이러한 격차를 해소합니다. 이러한 제어에는 PoLP(최소 권한 원칙)를 구현하기 위한 권한 관리가 포함되어 사용자가 자신의 작업에 필요한 파일에만 액세스할 수 있도록 하고 과도한 권한이 있거나 공개적으로 액세스할 수 있는 데이터를 처리합니다. 추가 기능으로는 민감한 정보를 적절히 분류하기 위한 데이터 매핑, 부적절한 리포지토리에 저장된 파일을 해결하기 위한 잘못된 위치의 데이터 수정, 보존 기간이 지난 또는 ROT(중복되고, 오래되고, 중요하지 않은)로 분류된 위험한 파일을 관리하기 위한 데이터 아카이빙/삭제 워크플로우가 있습니다.
보고 및 분석은 DSPM 소프트웨어 내에서 어떻게 작동하나요?
DSPM 솔루션에는 조직의 전반적인 데이터 보안 상태에 대한 가시성을 제공하는 보고 및 분석 도구가 포함되어 있습니다. 이러한 보고 기능은 일반적으로 환경 전체에서 민감한 데이터가 어디에 있는지 보여주는 대시보드를 통해 ROT(중복되고, 오래되고, 중요하지 않은) 데이터, 과도한 권한을 가진 파일, 잘못된 위치에 있는 정보, 중복된 콘텐츠와 같은 특정 위험 요소를 강조합니다. 보안 팀은 이러한 인사이트를 사용하여 시간에 따라 지표를 추적하고 가장 큰 영향을 줄 수 있는 곳에 개선 노력의 우선순위를 정할 수 있습니다..
Forcepoint DSPM은 온프레미스 또는 클라우드에 배포되어 있나요?
DSPM 솔루션은 유연한 구현 옵션을 제공합니다.
- 신속한 배포를 위한 클라우드 네이티브 SaaS
- 민감한 환경을 위한 하이브리드 모델
- 데이터 주권에 대한 제어를 위한 온프레미스
- 오버헤드를 최소화하기 위한 에이전트리스 아키텍처
대부분의 기업은 가장 중요한 데이터 저장소로 시작하여 점진적으로 적용 범위를 확장합니다.
Forcepoint DSPM은 AI와 자동화를 어떻게 사용하나요?
자동화는 엔터프라이즈 환경 전체에서 지속적인 대규모 데이터 발견과 스캔을 가능하게 합니다. 조직은 이제 데이터가 생성, 이동 또는 수정될 때 실시간으로 데이터를 자동으로 분류할 수 있어 수동 검토에서 발생하는 지연과 격차를 제거할 수 있습니다. 인공 지능의 주요 가치는 오탐을 줄이면서 매우 정확한 데이터 분류를 제공하는 데 있습니다. AI는 정말 민감한 데이터와 기존의 규칙 기반 시스템을 트리거할 수 있는 무해한 정보를 자신 있게 구별하는 데 필요한 정밀성을 제공합니다. DSPM 솔루션이 이러한 기능을 자신 있게 통합하기 위해서는 최신 솔루션이 PDF에서 비디오에 이르기까지 다양한 파일 유형을 처리할 수 있어야 하며 올바른 분류를 할당하고 규정 준수 요구 사항에 맞게 조정하기 위해 더 광범위한 데이터 필드를 이해해야 합니다. 여기에는 GenAI 기능, 심층 신경 네트워크 분류기, 기타 예측 AI 기술이 함께 작동하는 것을 포함합니다.
조직이 DSPM 플랫폼을 구현함으로써 얻을 수 있는 주요 이점은 무엇인가요?
데이터 보안 상태 관리의 이점은 다음 4가지 결과로 요약할 수 있습니다.
- 생산성 향상
- 비용 절감
- 위험 감소
- 규정 준수 간소화
Does DSPM integrate with other security technologies?
DSPM은 거의 독립적으로 작동하지 않습니다. 대부분의 조직은 이를 보완적인 보안 기술과 통합하여 포괄적인 데이터 보호 전략을 수립합니다. DSPM 소프트웨어가 데이터 위치, 민감도, 위험에 대해 제공하는 통찰력은 자연스럽게 다음과 같은 다른 보안 도구를 향상시킵니다.
- Data Detection and Response (DDR)
- Data Loss Prevention (DLP)
- Cloud Access Security Broker (CASB)
- Identity and Access Management (IAM)
- Cloud Security Posture Management (CSPM)
DSPM은 기존 데이터 분류 도구와 어떤 차이점이 있나요?
사전 정의된 규칙을 사용하여 알려진 데이터 리포지토리와 함께 작동하는 기존 도구와 달리, DSPM은 환경 전반에서 알려진 데이터와 알려지지 않은 데이터를 모두 지속적으로 발견하고, AI를 활용하여 더 정확한 분류를 하고 액세스 패턴과 보안 제어에 대한 컨텍스트를 제공합니다.
DSPM은 보안 상태를 평가하는 데 어떤 도움을 주나요?
데이터 보안 상태 관리(DSPM)는 민감한 데이터가 어디에 있는지(클라우드, SaaS, 온프레미스)를 지속적으로 발견하고, 민감도에 따라 분류하고, 액세스 권한을 가진 사람을 매핑하여 보안 상태를 평가합니다.
Forcepoint DSPM은 AI 메시 엔진과 광범위한 커넥터를 사용하여 정형 및 비정형 데이터를 인벤토리합니다. 과도하게 노출된 파일, ROT 데이터 및 위험한 권한을 강조하여 데이터 위험 평가에 연관시킵니다.
그런 다음 고성능 모니터링과 분석을 통해 민감한 데이터가 얼마나 위험에 노출되어 있는지, 어떤 위치와 비즈니스 부서가 가장 노출을 유발하는지, 시간이 지남에 따라 변화가 전반적인 데이터 위험에 어떤 영향을 미치는지를 보여줍니다. 이러한 통찰력은 상세한 대시보드와 보고를 통해 드러나므로 보안 및 규정 준수 팀은 시점 감사 대신에 데이터 보안 상태에 대한 현재의 측정 가능한 보기를 얻을 수 있습니다.
SSPM과 CSPM 및 DSPM의 차이점은 무엇입니까?
CSPM(클라우드 보안 상태 관리)은 클라우드 인프라(구성, 네트워크 제어, ID, 플랫폼 서비스)에 중점을 두고 있습니다. 데이터 자체의 내용이 아니라 IaaS, PaaS 및 SaaS 환경에서 잘못된 구성을 찾아서 수정하도록 도와줍니다.
SSPM(SaaS 보안 상태 관리)은 Microsoft 365, Salesforce 등과 같은 서비스에서 SaaS 앱에 대한 보안 설정, 액세스 및 통합에 중점을 둡니다.
DSPM(데이터 보안 상태 관리)은 데이터가 어디에 저장되어 있든 중요한 정보와 관련된 위험을 발견, 분류 및 평가하는 데 특히 중점을 두고 있습니다. “우리가 가지고 있는 데이터는 무엇이며, 어디에 있고, 누가 액세스할 수 있으며, 노출은 얼마나 위험한가?”에 대한 답을 제공합니다.
Forcepoint DSPM에는 실시간 모니터링과 위험 탐지 기능이 있습니까?
예. Forcepoint DSPM은 스캔 시 실시간 또는 고빈도 위험 평가가 제공되며, 노출 수준으로 대시보드를 업데이트하고 고급 경고 시스템을 활용하여 비정상과 잠재적인 침해에 대해 자동으로 플래그를 지정합니다.
DSPM은 클라우드 보안을 어떻게 향상시켜 주나요?
DSPM은 클라우드 스토리지, SaaS 플랫폼 및 데이터베이스에 저장된 민감한 데이터에 대한 완전한 가시성을 제공하여 클라우드 보안을 강화합니다. 데이터가 어떤 존재하는지, 얼마나 민감한지, 어디에 있거나 어떻게 공유되는지 정확히 보여줍니다.
Forcepoint DSPM은 주요 클라우드 공급자와 ID 소스를 스캔하여 과도한 노출된 데이터, 과도한 권한, 기존 클라우드 도구에서 놓치던 중요한 콘텐츠를 찾아냅니다.
이러한 컨텍스트를 통해 보안 팀은 클라우드에서 최소 권한 액세스를 적용하고, 실제 비즈니스 및 규제 영향을 기반으로 수정 우선을 정하고, DSPM 발견을 DLP 및 기타 제어와 통합할 수 있습니다.
클라우드 보안에 DSPM을 사용할 때의 이점은 무엇인가요?
클라우드 환경에서 DSPM을 사용하면 데이터 노출 감소(과도한 노출 탐지 및 권한 정리), 멀티 클라우드와 SaaS 전반에서 사각지대 감소, IP 및 규제 데이터에 대한 더 나은 보호 등 구체적인 결과를 얻을 수 있습니다.
Forcepoint AI Mesh는 Forcepoint DSPM의 분류 정확성을 개선해 오탐을 직접 줄이고 팀이 실제 위험에 집중할 수 있도록 도와줍니다.
또한 자동화, 통합 대시보드 및 보고를 통해 운영 효율성을 개선합니다. ROT 데이터를 처리하여 조사와 수정 주기를 단축하고, 스토리지 및 거버넌스 비용을 절감하며, 감사 및 데이터 보호 규정에 대한 규정 준수 준비를 해결합니다.
DSPM이 신원 위협 탐지와 대응에 도움이 되나요?
DSPM은 신원 위협 탐지 및 대응(ITDR) 플랫폼이 아니지만 Forcepoint DSPM은 데이터와 관련된 신원 관련 위험을 탐지합니다. 민감한 파일에 액세스할 수 있는 사용자와 그룹을 매핑하고, 과도한 권한을 받거나 영향이 큰 "위험 사용자"를 강조하고, 분석과 경고를 통해 의심스러운 액세스 패턴을 찾아냅니다.
이러한 통찰력을 통해 보안 팀은 잠재적인 ID 오용(예: 중요한 데이터에 대한 과도한 액세스 권한을 가진 사용자)을 신속하게 조사하고 액세스 취소, 공유 강화, 기존 보안 도구의 워크플로 트리거와 같은 표적 조치를 취할 수 있어 추측 없이 ID 중심의 데이터 보호를 강화할 수 있습니다.
DSPM은 민감한 데이터 노출을 어떻게 탐지하고 평가하나요?
Forcepoint DSPM은 커넥터를 사용하여 클라우드 및 온프레미스 데이터 저장소를 대규모로 스캔한 다음 AI 메시 분류와 구성 가능한 탐지기를 적용하여 콘텐츠와 컨텍스트를 기반으로 민감한 데이터(PII, PCI, PHI, IP 등)를 식별합니다.
그런 다음 공유 설정과 권한을 분석하여 공개되거나, 외부에서 공유되거나, 내부에서 과도하게 공유되거나, 잘못된 위치에 있거나, 위험한 사용자와 관련된 데이터에 플래그를 지정하고, 대시보드와 보고서 내에서 해당 위험을 수량화하여 팀이 수정 우선순위를 정할 수 있도록 합니다.
DSPM은 규정 준수 보고를 어떻게 단순화하나요?
Forcepoint DSPM은 규제 데이터가 어디에 있고, 어떻게 보호되고, 누가 액세스할 수 있는지를 지속적으로 문서화함으로써 GDPR, HIPAA 및 기타 개인정보와 주권과 같은 규정에 필요한 증거를 중앙 집중화해 줍니다. 보고서 기능과 분석 제품군은 인기 있는 프레임워크 전반에서 규정 준수 준비 상태와 데이터 위험을 보여줍니다.
규정 준수 팀용 Forcepoint DSPM에는 어떤 대시보드가 포함되어 있나요?
Forcepoint DSPM 분석 제품군에는 과도한 노출 분석, 랜섬웨어 노출 분석, 중요한 데이터 중복, 위험한 사용자 탐지, 데이터 보존, 잘못된 위치된 데이터, 데이터 위험 평가, 데이터 제어 위반에 대한 사고 추적과 같은 사전 정의된 대시보드가 포함되어 있습니다.
또한 규정 준수 팀은 DSPM의 쿼리 언어로 구동되는 내장 위젯(카운터, 차트, 테이블, 사고 보기 등)을 사용하여 커스텀 대시보드를 생성할 수 있으며, 이러한 보기를 보고서로 내보내면 커스텀 개발 없이 특정 규정, 사업부 또는 데이터 카테고리로 감독을 조정할 수 있습니다.
