









Forcepoint Data Classification

Software de Data Classification
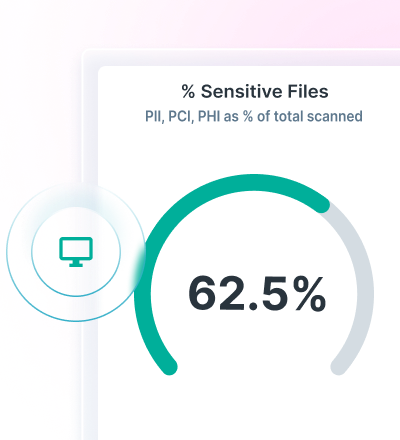
Classifique e Reporte com Confiança
Classifique a mais ampla gama de tipos de dados com eficiência e precisão superior usando a tecnologia AI Mesh.
Encontre e catalogue dados em toda a empresa na velocidade da luz.
O Forcepoint Data Classification usa AI Mesh para fornecer alta precisão no processo de classificação de dados. Sua arquitetura de IA em rede conta com um Pequeno Modelo de Linguagem (SLM) e componentes de IA avançados para melhorar a eficiência e reduzir os falsos positivos.

Por que o Forcepoint Data Classification?

O insight gerado com a IA impulsiona uma abordagem inovadora para a classificação de modo que você possa determinar com precisão e eficiência como os dados devem ser classificados, em escala.

A cobertura da mais ampla gama de tipos de dados do setor impulsiona a eficiência e agiliza a conformidade, enquanto oferece melhor proteção para os dados das organizações.

Integre com o Enterprise Data Loss Prevention (DLP) para selecionar os requisitos e critérios para data classification e aplicar políticas de DLP com facilidade, sem a necessidade de um longo retreinamento.

Aumente a velocidade e a eficiência da classificação de dados para reduzir falsos positivos e dedicar mais tempo a incidentes de segurança de dados legítimos.

Evite multas dispendiosas de não conformidade com importantes regulamentos out-of-the-box e a mais ampla cobertura de tipos de dados do setor.

Data Security Everywhere You Need It
Secure data everywhere with Forcepoint. Prevent breaches, simplify compliance, unify policy management and adapt to risk in real time with our data security solutions.

Forcepoint DLP: proteja dados confidenciais e agilize a conformidade com DLP SaaS baseado em nuvem.
Data Security Posture Management (DSPM): descubra, classifique e orquestre com automação baseada em IA.
Risk-Adaptive Protection: ajuste automaticamente as políticas com base no comportamento do usuário para adaptar-se em tempo real aos riscos emergentes.
Perguntas frequentes
O que é Data Classification?
Data Classification é a prática de marcar e organizar os dados em categorias predefinidas, facilitando a localização e recuperação, aplicando o acesso seguro para usuários autorizados.
Por que a classificação de dados é importante para as organizações?
As práticas de Data Classification são necessárias para manter uma postura de segurança forte. Ao garantir que as equipes de segurança saibam onde encontrar informações confidenciais e ao implementar regras sobre quem tem permissão para acessá-las, você pode evitar ou conter violações de dados e manter usuários não autorizados longe de recursos que não deveriam ter.
Quais são os tipos de classificação de dados?
Classificação baseada em conteúdo: Esta é a prática de examinar arquivos e procurar informações confidenciais dentro deles. Isso pode ser útil se você tiver um problema de informações que não são para consumo público ocultas em tipos de arquivos aparentemente inofensivos.
Classificação baseada em contexto: em vez de examinar o conteúdo de arquivos diretamente, essa abordagem analisa principalmente os metadados associados aos arquivos para encontrar pistas que indiquem que os dados dentro são confidenciais. Isso pode incluir identificar o local onde um arquivo é salvo, qual usuário o criou ou para qual aplicativo o arquivo foi desenvolvido. Essa abordagem funciona bem quando sua base de usuários é bem treinada e quando você já tem um grau de controle sobre seus dados confidenciais.
Classificação baseada em usuários: isso coloca o ônus sobre os usuários para vasculhar arquivos e categorizá-los. Embora, na sua melhor forma, essa abordagem possa reduzir significativamente os falsos positivos, ela depende não apenas de uma base de usuários altamente treinada, mas também do tempo para classificar os dados manualmente. Isso significa que geralmente só é adequada para uma organização mais enxuta ou um conjunto de dados menor
Quais são as melhores práticas para implementar o Data Classification?
Identificação: Encontre onde seus dados confidenciais residem, incluindo repositórios na nuvem e discos rígidos físicos, e tome as medidas imediatas necessárias para protegê-los com criptografia, controles de acesso físico, etc.
Organização: Elabore o processo que você usará para organizar os dados em categorias.
Treinamento: Capacite os funcionários a desempenhar um papel na marcação de dados e colocando-os no lugar certo com base em sua categoria. Quanto mais pessoas tiverem um papel no processo, mais rigoroso o seu treinamento precisa ser para garantir que o erro humano não comprometa os seus esforços.
Conformidade: Entenda os regulamentos de segurança e privacidade de dados aplicáveis às suas operações, juntamente com as penalidades por não conformidade.
Soluções: Encontre a solução de Data Classification mais adequada à sua organização. Em muitos casos, pode ser melhor utilizar uma plataforma de Data Security abrangente que possa auxiliar com a descoberta, classificação e priorização de dados, em vez de reunir diferentes soluções de vários fornecedores.
A classificação de dados pode ajudar com a conformidade regulatória?
Sim, o Forcepoint Data Classification pode ajudar a simplificar a conformidade em mais de 80 regiões. Ele ajuda você a evitar multas dispendiosas por não conformidade com os principais regulamentos out-of-the-box e a mais ampla cobertura de tipos de dados do setor.
Quão precisa é o Forcepoint Data Classification?
O Forcepoint Data Classification usa precisão e eficiência com tecnologia de inteligência artificial. Ele ajuda a classificar os dados em várias fontes, usando a tecnologia AI Mesh, para melhorar continuamente sua precisão e eficiência, economizando para as organizações tempo e recursos valiosos.
O que é o AI Mesh e como ele é usado?
O Forcepoint Data Classification usa AI Mesh para fornecer alta precisão no processo de classificação de dados. Sua arquitetura de IA em rede conta com um Pequeno Modelo de Linguagem (SLM) e componentes de IA avançados para melhorar a eficiência e reduzir os falsos positivos.
