










X-Labs
Get insight, analysis & news straight to your inbox

The Missing Ingredient to Your Data Classification Software

Lionel Menchaca
July 24, 2025

Four Success Factors Help Forcepoint Employees Get Even Better

Emilie McLaughlin
July 23, 2025


Uncover Hidden Risks: A Free GRC Tool to Strengthen Your Compliance Strategy

Kevin Oliveira
July 22, 2025

Learning from the EchoLeak Wake-Up Call

Corey Kiesewetter
July 18, 2025

Forcepoint Insights Analytics Platform Now Available to CASB Customers

Neeraj Nayak
July 17, 2025

We Reviewed How Companies are Accessing AI. Here’s What We Found.

Florent Fortune
July 16, 2025

Turn Compliance Chaos into Confidence by Automating Reporting
Corey Kiesewetter
July 15, 2025

Navigating VUCA: What Gartner® Says About the 2025–2026 Threat Landscape
Lionel Menchaca
July 14, 2025

Build a Smarter, Sustainable Data Security Program in 6 Steps

Tuan Nguyen
July 10, 2025

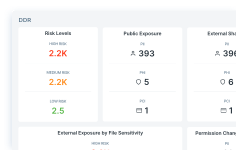
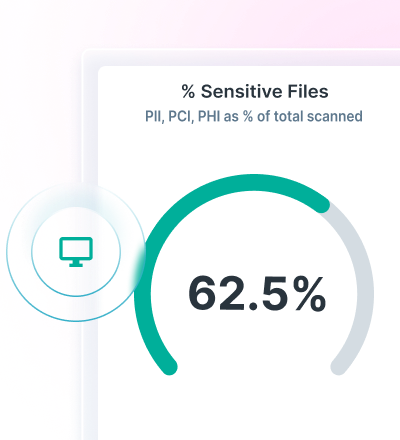
Analyzing Data Risk with DSPM
Lionel Menchaca
July 9, 2025

Signal in the Noise: How to Turn DLP Alerts into Action

Bryan Arnott
June 26, 2025