

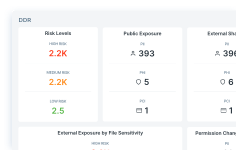





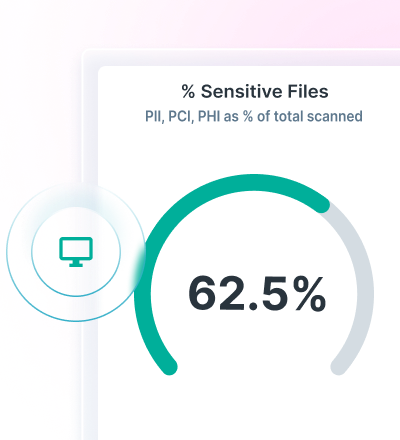



Forcepoint Data Classification

Data Classification Software
Mit Zuversicht klassifizieren und melden
Klassifizieren Sie die breiteste Palette von Datentypen mit überragender Präzision mit KI Mesh-Technologie.
Finden und katalogisieren Sie Daten im gesamten Unternehmen blitzschnell.
Forcepoint Data Classification verwendet AI Mesh, um eine hochgenaue Datenklassifizierung zu bieten. Die vernetzte KI-Architektur basiert auf einem Small Language Model und fortschrittlichen KI-Komponenten, um die Effizienz zu verbessern und Fehlalarme zu reduzieren.

Warum Forcepoint Data Classification?

Klassifizieren Sie Daten in mehreren Quellen und verwenden Sie AI Mesh, um ihre Genauigkeit und Effizienz kontinuierlich zu verbessern, wodurch Unternehmen wertvolle Zeit und Ressourcen sparen.

Die Abdeckung der breitesten Palette von Datentypen in der Branche hilft dabei, die Compliance zu optimieren und gleichzeitig einen besseren Schutz für die Daten von Unternehmen zu bieten.

Integrieren Sie in Enterprise Data Loss Prevention (DLP), um die Anforderungen und Kriterien für die Datenklassifizierung auszuwählen und DLP-Richtlinien einfach durchzusetzen, ohne dass eine umfangreiche Neuschulung erforderlich ist.

AI Mesh klassifiziert Daten schnell und genau, optimiert Prozesse und reduziert den manuellen Aufwand, um es Teams zu ermöglichen, sich auf höherwertige Aufgaben oder bedeutendere Vorfälle zu konzentrieren.

Vermeiden Sie kostspielige Bußgelder für Nichteinhaltung von Compliance-Vorgaben mit standardmäßigen Schlüsselvorgaben und der breitesten Abdeckung von Datentypen in der Branche.

Datensicherheit überall, wo Sie sie benötigen
Schützen Sie Daten überall mit Forcepoint. Verhindern Sie Sicherheitsverletzungen, vereinfachen Sie die Compliance, vereinheitlichen Sie die Richtlinienverwaltung und passen Sie sich in Echtzeit an Risiken an.

Forcepoint DLP: Schützen Sie sensible Informationen und setzen Sie die Compliance mit DLP-Software-as-a-Service (SaaS) durch.
DSPM (Data Security Posture Management): Automatisieren Sie die Erkennung, Klassifizierung und Orchestrierung von Daten, um die vollständige Kontrolle und Transparenz über Ihre Daten im gesamten Unternehmen zu erhalten.
Risk-Adaptive Protection: Passen Sie Richtlinien automatisch basierend auf dem Nutzerverhalten an, um sie in Echtzeit an aufkommende Risiken anzupassen.
Häufig gestellte Fragen
Was ist Data Classification?
Data Classification ist die Praxis der Kennzeichnung und Organisation von Daten in vordefinierten Kategorien, die das Auffinden und Abrufen von Daten erleichtert und gleichzeitig den sicheren Zugriff für autorisierte Benutzer durchsetzt.
Warum ist Data Classification für Unternehmen wichtig?
Data Classification-Praktiken sind notwendig, um eine starke Sicherheitslage zu wahren. Indem Sie sicherstellen, dass Sicherheitsteams wissen, wo sie sensible Informationen finden, und indem Sie Regeln darüber festlegen, wer Zugriff darauf hat, können Sie Datenverletzungen verhindern oder eindämmen und nicht autorisierte Benutzer von Ressourcen fernhalten, die sie nicht haben sollten.
Was sind die Typen der Data Classification?
Inhaltsbasierte Klassifizierung: Dies ist die Praxis, Dateien zu untersuchen und nach sensiblen Informationen in ihnen zu suchen. Dies kann hilfreich sein, wenn Sie ein Problem mit Informationen haben, die nicht für die öffentliche Nutzung bestimmt sind, die sich in scheinbar harmlosen Dateitypen verstecken.
Kontextbasierte Klassifizierung: Anstatt Dateiinhalte direkt zu untersuchen, betrachtet dieser Ansatz in erster Linie die Metadaten, die mit Dateien verknüpft sind, um Hinweise darauf zu finden, dass Daten darin vertraulich sind. Dies kann die Identifizierung des Speicherortes umfassen, an dem eine Datei gespeichert ist, welcher Benutzer sie erstellt hat oder für welche Anwendung die Datei erstellt wurde. Dieser Ansatz funktioniert gut, wenn Ihre Benutzerbasis gut geschult ist und wenn Sie bereits ein gewisses Maß an Kontrolle über Ihre sensiblen Daten haben.
Benutzerbasierte Klassifizierung: Dies legt die Verantwortung auf Benutzer, Dateien zu durchforsten und sie zu kategorisieren. Während dieser Ansatz im besten Fall False Positives erheblich reduzieren kann, ist er nicht nur auf eine hochqualifizierte Benutzerbasis angewiesen, sondern auch auf die Zeit, um Daten manuell zu klassifizieren. Das bedeutet, dass es normalerweise nur für ein schlankeres Unternehmen oder einen kleineren Datensatz geeignet ist.
Was sind Best Practices für die Implementierung von Data Classification?
Identifizierung: Finden Sie heraus, wo sich Ihre sensiblen Daten befinden, einschließlich Cloud-Repositories und physischer Festplatten, und unternehmen Sie alle erforderlichen sofortigen Schritte, um sie mit Verschlüsselung, physischem Zugriff usw. zu schützen. Organisation: Erstellen Sie den Prozess, mit dem Sie Daten in Kategorien organisieren können. Schulung: Ermöglichen Sie es Mitarbeitern, eine Rolle bei der Kennzeichnung von Daten zu übernehmen und sie basierend auf ihrer Kategorie an der richtigen Stelle zu platzieren. Je mehr Personen eine Rolle im Prozess haben, desto strenger muss Ihre Schulung sein, um sicherzustellen, dass menschliche Fehler Ihre Bemühungen nicht gefährden.
Compliance: Verstehen Sie die geltenden Datensicherheits- und Datenschutzbestimmungen für Ihre Betriebe sowie die Strafen für Verstöße.
Lösungen: Finden Sie die Data Classification-Lösung, die für Ihr Unternehmen am besten geeignet ist. In vielen Fällen kann es am besten sein, eine umfassende Plattform für Datensicherheit zu verwenden, die bei der Erkennung, Klassifizierung und Priorisierung von Daten unterstützen kann, anstatt verschiedene Lösungen verschiedener Anbieter zusammenzubringen.
Kann Data Classification bei der Einhaltung von Vorschriften helfen?
Ja, Forcepoint Data Classification kann helfen, die Compliance in über 80 Regionen zu optimieren. Es hilft Ihnen, kostspielige Bußgelder für Nichteinhaltung von Compliance-Vorgaben mit standardmäßig wichtigen Vorschriften und der breitesten Abdeckung von Datentypen in der Branche zu vermeiden.
Wie genau ist Forcepoint Data Classification?
Forcepoint Data Classification verwendet KI-gestützte Präzision und Effizienz. Es hilft dabei, Daten in mehreren Quellen mit AI-Mesh-Technologie zu klassifizieren, um ihre Genauigkeit und Effizienz kontinuierlich zu verbessern und Unternehmen wertvolle Zeit und Ressourcen zu sparen.
Was ist AI Mesh und wie wird es verwendet?
Forcepoint Data Classification verwendet AI Mesh, um eine hochgenaue Datenklassifizierung zu bieten. Die vernetzte KI-Architektur basiert auf einem Small Language Model und fortschrittlichen KI-Komponenten, um die Effizienz zu verbessern und Fehlalarme zu reduzieren.
